
Читайте также
-
Дент 1468: нефть марки Brent после открытия рынков 2 марта 2026 года подорожала на 6%, до $77,6 за баррель

02.03.2026 08:35:43 | vc.ru
День 1468: нефть марки Brent после открытия рынков 2 марта 2026 года подорожала на 6%, до $77,6 за баррель
02.03.2026 08:35:43 | vc.ru
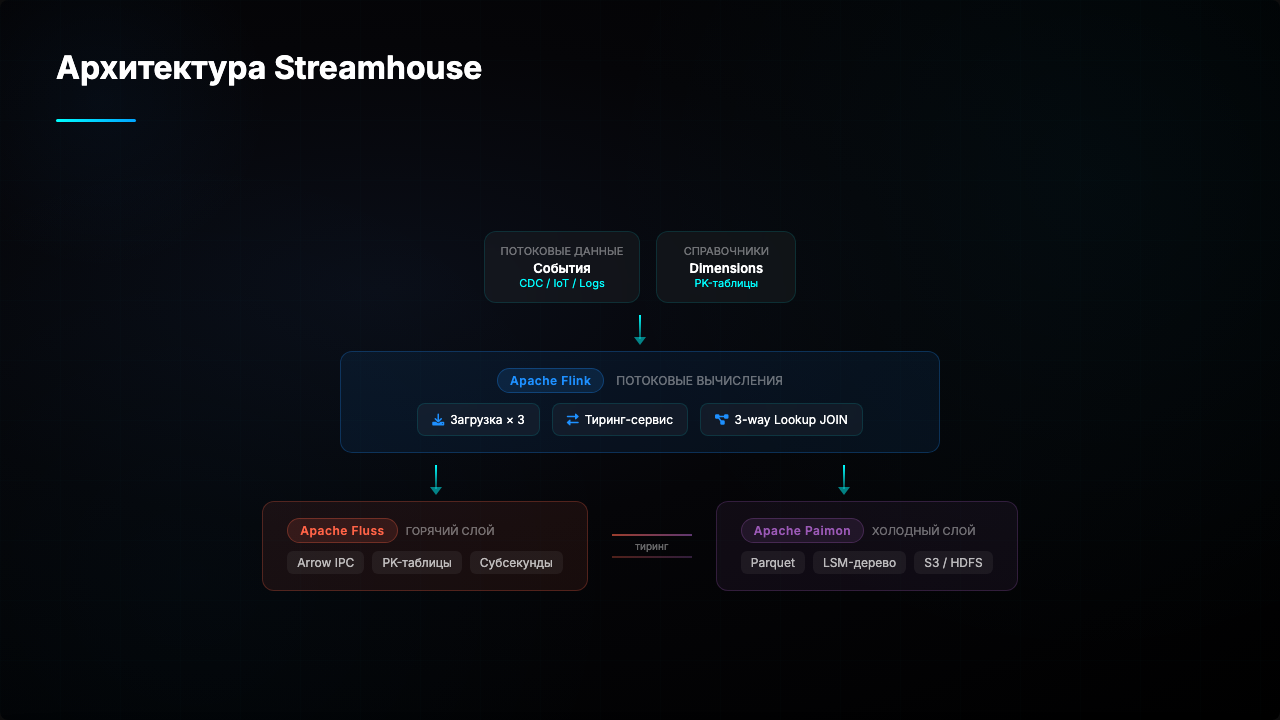
Изучаем FastAPI за одну статью: от «Hello World» до структурированного API
02.03.2026 08:26:44 | Хабр
Архитектура европейского рационального мышления: 8 типов идей как каркас базы знаний
02.03.2026 08:10:46 | Хабр
Цена объективности: что потеряла наука в погоне за «чистыми данными», и почему в лабораториях нужны художники
02.03.2026 08:02:27 | Хабр
«Неплохо сделано, а?» — самолет, который обогнал звук, «Конкорд» и собственную эпоху
02.03.2026 08:00:26 | Хабр
От «вроде работает» к метрикам: внедряем бенчмарки качества для AI-агентов
02.03.2026 08:00:25 | Хабр
Нет соединения — не значит нет UX. Как не потерять доверие пользователя вместе с интернетом
02.03.2026 07:45:23 | Хабр
Второе мнение и онкологический консилиум: семь раз отмерь, один раз отрежь
02.03.2026 07:30:20 | Хабр
Materialized views и проекции в ClickHouse: когда что использовать и как не наступить на грабли
02.03.2026 07:14:14 | Хабр
Черная метка: рынок онлайн-пиратства в Рунете в 2025 году сжался до $34,4 млн
02.03.2026 07:09:10 | Хабр
[Перевод] Секретный ультиматум на $200 млн: почему Минобороны США угрожает уничтожить главную ИИ-компанию мира
02.03.2026 06:46:23 | Хабр
Проблема не в промпте: как Claude Code плывет на длинных задачах и как управлять контекстом
02.03.2026 06:34:43 | Хабр
Zero Trust для российских компаний: как защитить удалённый доступ с помощью ZTNA
02.03.2026 06:29:04 | Хабр
Когда всё идёт не так: на примере одного корпуса расскажу, откуда могут вылезти проблемы и как мы с ними боролись
02.03.2026 06:21:02 | Хабр
Как бездумное использование AI убивает экспертизу и превращает разработку в vibe coding
02.03.2026 06:21:01 | Хабр
Как обойти платную подписку Битрикс24 и вернуть своего бота к жизни: делаем свой провайдер событий на коробке
02.03.2026 06:10:58 | Хабр
Как мы овощехранилище автоматизировали, разработали свою SCADA и железо. Часть 2: Информативный интерфейс SCADA
02.03.2026 05:47:01 | Хабр
Цифровой двойник оборудования в облаке: вычислительный кластер мультфизических эмуляций
02.03.2026 05:15:49 | Хабр
Военные очень хотят автономных роботов-убийц, а также паника по поводу массовых ИИ-увольнений
02.03.2026 05:09:43 | Хабр
Путь айтишника: как преодолевать все изменения на рынке и оставаться востребованным
02.03.2026 05:05:45 | Хабр

НОВОСТИ
-
Вербное воскресенье в 2026 году: смысл и традиции православного праздника

13.04.2026 00:10:00 | Lenta.ru
В российском регионе обломки беспилотников упали на территорию двух предприятий
05.04.2026 22:41:34 | Lenta.ru
В Белгородской области из-за удара дрона ВСУ погиб доброволец народной дружины
05.04.2026 22:39:00 | ТАСС
Карседо не считает матч "Спартака" с "Локомотивом" в РПЛ лучшим для команды
05.04.2026 22:38:59 | ТАСС
В Иране заявили, что не будут испытывать дефицита ракет, даже если война продлится годы
05.04.2026 22:38:42 | ТАСС
Разведка Сербии назвала страну производства взрывчатки для диверсии газопровода
05.04.2026 22:38:36 | Life.ru
Channels: запасы нефти в Нигерии сокращаются из-за растущих темпов добычи
05.04.2026 22:38:09 | ТАСС
Спасенная из реки в Дербентском районе Дагестана девушка находится без сознания
05.04.2026 22:37:29 | ТАСС
В здании ТЦ в Калининграде из-за сильных порывов ветра увеличились очаги возгорания
05.04.2026 22:30:59 | ТАСС
В Тегеране предупредили, что Ближний Восток сгорит дотла из-за США
05.04.2026 22:30:00 | Российская Газета
Отключения электроснабжения затронули 8 округов Запорожской области и два города
05.04.2026 22:29:42 | Life.ru
Отключения электроснабжения затронули 8 округов Запорожской области и три города
05.04.2026 22:29:42 | Life.ru
Число пострадавших при пожаре в калининградском ТЦ выросло до пяти человек
05.04.2026 22:28:54 | Коммерсантъ
Пострадавшие при ликвидации возгорания в ТЦ Калининграда пожарные получили отпущены домой
05.04.2026 22:28:48 | ТАСС
В Сербии назвали страну производства найденной у газопровода взрывчатки
05.04.2026 22:23:00 | Lenta.ru
Карседо выразил надежду на честное судейство в кубковом матче с "Зенитом"
05.04.2026 22:22:00 | ТАСС
Британские ВМС сообщили о критической ситуации в районе Персидского залива
05.04.2026 22:19:24 | ТАСС
Вице-премьер Белоруссии: БелАЭС за пять лет выработала более 58 млрд кВт⋅ч электричества
05.04.2026 22:17:31 | ТАСС
Энергодар и несколько муниципалитетов Запорожской области остались без света
05.04.2026 22:14:38 | Life.ru
Предгорный округ Ставрополья направит в зону СВО более 10 тыс. пасхальных подарков
05.04.2026 22:12:58 | ТАСС
В Чечне в селе Илсхан-Юрте из-за оползней повреждены восемь частных домов
05.04.2026 22:08:46 | ТАСС
ПИШИТЕ
Техническая поддержка проекта ВсеТут